





RecAccel™ N3000 helps to do as much as possible within an energy budget in order to decrease latency and increase prediction accuracy.

The patented FFP8 format has configurable exponent and mantissa widths, and the option to use the sign bit for data to improve recommendation accuracy.

RecAccel™ supports exceeds 20 million inferences per second at 20 Watts for leading recommender AI model that provide the extreme low power deep learning inference accelerators.

As the market is growing, there is for sure a need for an alternative cloud system that provides increased compute density under a controlled package size, fixed energy budget and with stringent constraints on recommendation accuracy. RecAccel™ N3000 employs TSMC 7nm process, specifically designed for accelerating deep learning models.
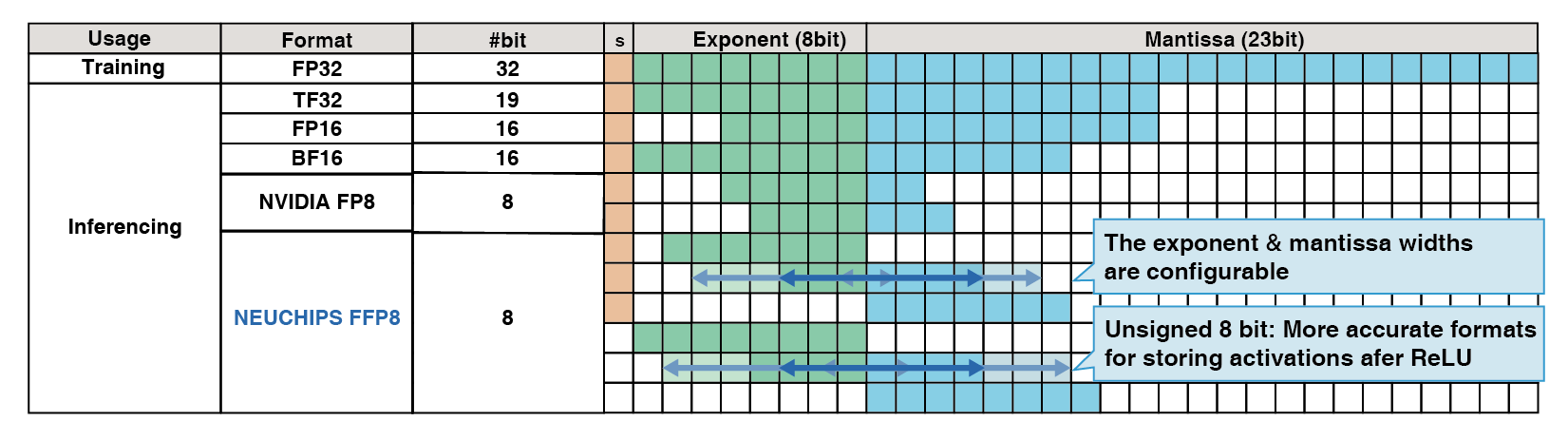
RecAccel™ N3000 uses a multi-calibration strategy for int8 representations. This multi-calibration strategy has been shown to decrease accuracy loss by an order of magnitude over basic int8 quantization, yielding 99.97% accuracy. Additionally, our patented FFP8 floating-point format gives us even more flexibility during quantization. This yields an additional order of magnitude decrease in lost accuracy netting 99.996% accuracy.
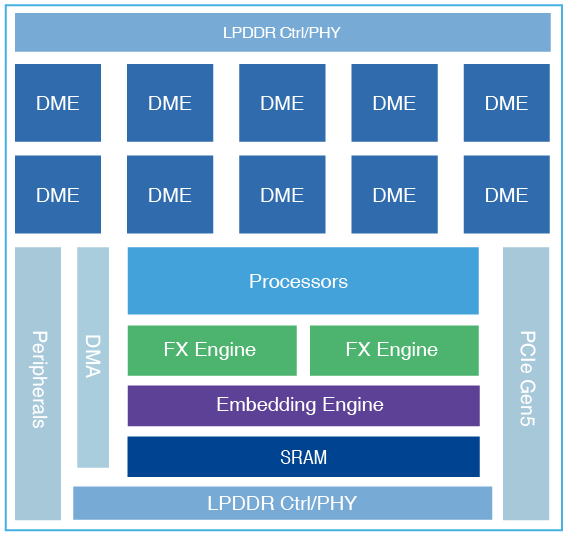
RecAccel™ recommendation inference accelerator chip includes hardware engines designed for the key parts of the recommendation workload. NEUCHIPS’ embedding engine reduces access to off-chip memory by 50% and increase bandwidth utilization by 30% via a novel cache design and DRAM traffic optimization techniques. RecAccel™ N3000 has 10 compute engines with 16K MAC per engines. The compute engines consume 1 microjoule per inference at the SoC level which helps to deploy with very low power consumption but handle sparse matrices efficiently.